
- Welche Komponenten einer Sprachassistenz-Plattform kann auch in Smarten Dingen selbst laufen?
- Wie stark sind die Einschränkungen gegenüber einer vollständigen Sprachassistenz-Plattform?
- Welche Tools sollten Entwickler nutzen um ihren Dingen das Sprechen beizubringen?
- Wie kommt man zu einer Echten Unterhaltung mit dem Smarten Ding?
Schon im vorigen Analyst View zu dem Thema wurden die Restriktionen der cloud-basierten Sprachassistenz-Plattformen sichtbar. Eine natürliche Konversation nutzt intensiv die Künstliche Intelligenz in der Cloud. Obwohl das für die meisten Industriellen Anwendungen keine Option ist, wächst die Attraktivität aus dem Consumer-Bereich in die professionellen Anwendungen. Die offenen Skill-Konzepte von Alexa und AliGenie ermöglichen fast beliebige IoT Devices mit Sprache zu steuern. Besonders in der Home-Automation sind Anwendungen wie “Alexa – Licht aus” von allen führenden Home-Automation Plattformen und Open-Source Frameworks unterstützt. Entsprechend wächst auch die Nachfrage im professionellen Bereich Software über Sprache zu steuern.
Müssen Sprachassistenz-Plattformen aber überhaupt immer in der Cloud als geteilte Dienste liegen? Im vorangegangenen Analyst View stellte sich dies als Haupthindernis beim industriellen Einsatz heraus. Es lohnt sich also der Frage auf den Grund zu gehen. Entgegen der Darstellung der großen Cloud-Hyperscaler ist eine Sprachassistenz-Plattform nicht zwingend ein großer monolithischer Cloud-Dienst, sondern ist aus einer Hand voll Komponenten zusammengesetzt. Diese schauen wir im Detail an und geben konkrete Hinweise was davon heute schon “on the Edge” und damit offline möglich ist (siehe Abbildung).
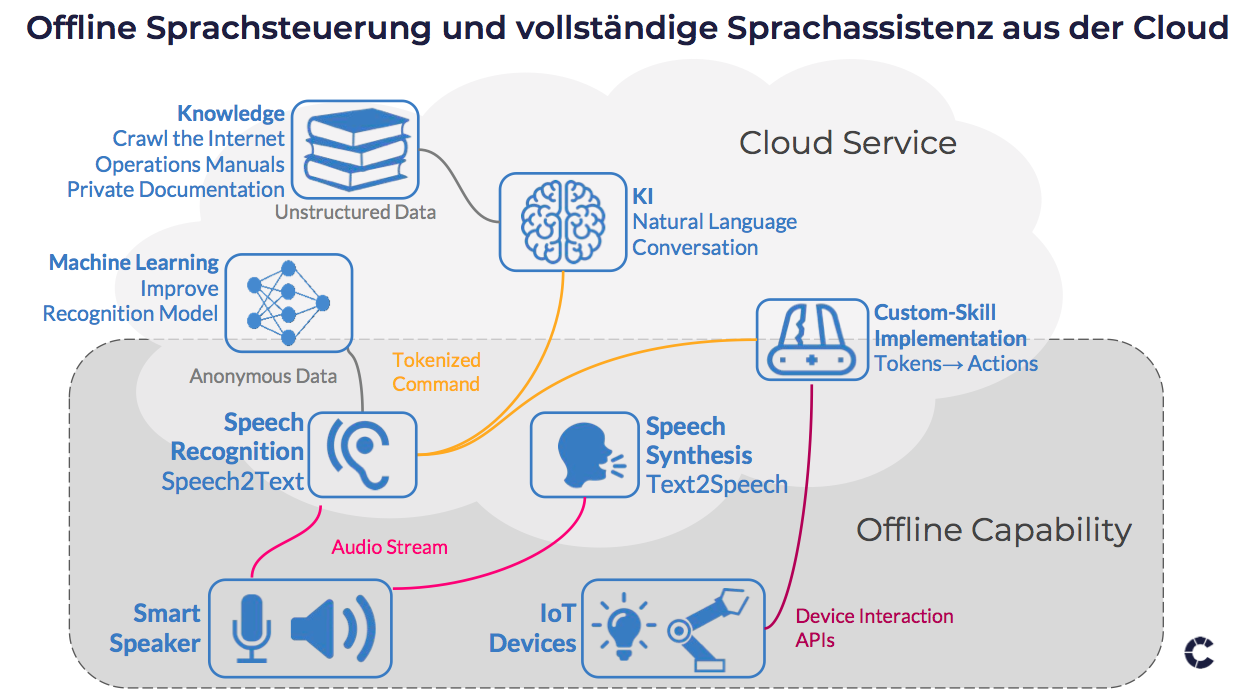

Smart Speaker sind eigentlich gar nicht Smart
Der Smart Speaker ist technisch eher vergleichbar mit einem IP-Telefon von vor 20 Jahren kombiniert mit einem gut klingenden Web-Radio. Die meisten Geräte haben kein bisschen Intelligenz vor Ort und übertragen einfach einen Audio Strom.
Speech Synthesis ist heute schon fast trivial
Sprach-Synthese, also das Vorlesen eines Textes mit einer elektronisch generierten Stimme, die einer menschlichen Stimme nahe kommt, gibt es schon lange. Bereits 1961 wurde an den Bell Labs auf einem IBM 704 Großrechner daran programmiert. Auch heute bieten Text2Speech-Dienste in der Cloud, die kurzzeitig eine hohe Rechenleistung abrufen können, die natürlichste Sprachqualität. Aber auch die Offline-Alternativen sind inzwischen sehr gut verständlich. Dabei kommen kommerzielle Softwareprodukte den Cloud-Dienste schon sehr nahe. Auf dem Markt sind auch Open-Source Bibliotheken, die zwar noch deutlich als synthetische Stimme erkennbar sind, aber eine gut verständliche Sprach-Synthese auf einem Edge-Device von der Größe eines Raspberry Pi in Echtzeit bereitstellen. Ein guter Überblick ist hier zu finden. Wir empfehlen Software-Entwicklern den ersten Proof-Of-Concept mit der Pico-TTS Engine zu probieren. Diese ist die Offline-Sprach-Synthese aus Google’s Android Software und steht bereits seit 2014 als Raspberry Pi Port unter der Apache 2 Lizenz zur Verfügung.
Speech Recognition muss immer weiter lernen
Der Weg anders herum, aus dem gesprochenem Wort zunächst einmal einen Text zu machen, ist um einiges schwieriger. Hier gibt es akustische Modelle, die sub-phonetische Einheiten clustern, ein phonetisches Wörterbuch das alle Worte enthält in denen bestimmte Phone (Klänge) vorkommen, und letztlich ein Sprachmodell, dass sinnvolle Wörter und Abfolgen in einer Sprache einschränkt. Erst die Kombination aller drei Verfahren bringt sinnvolle Ergebnisse. Das Phonetische und Sub-Phonetische Modell ist dabei keineswegs statisch. Durch das Verbessern von nicht korrekt erkannten Aussprachen durch den Nutzer lernt die Spracherkennung wie ein kleines Kind, auch unscharfe Aussprachen oder Dialekte zu verstehen. Leider verstehen die meisten Systeme heute nicht einmal den Kontext zwischen einem nicht erkannten Satz und der deutlicheren Wiederholung, die dann erkannt wird (siehe unten). Eine gute Spracherkennung ist also langfristig durch die Qualität dieses Machine-Learnings bestimmt. Wichtig ist, dass das Recognition-Model mit vollkommen anonymisierten Daten weiter lernen kann. Deshalb ist der Lernprozess auch besonders effektiv, wenn nicht nur genug Rechenleistung zum Lernen, sondern auch sehr viele gesprochene, erkannte und ggf. korrigierte Sätze verfügbar sind. Sehr beeindruckend ist die Entwicklung der Public Cloud-Dienste die im Consumer-Bereich täglich viele Millionen Nutzer haben. In der Abbildung ist die Spracherkennung von Google gezeigt, die seit 2017 die Erkennungsrate eines Menschen erreicht hat.

Zusammenfassend bieten diese Speech2Text Cloud-Dienste gute bis sehr gute Ergebnisse. Die Unterschiede liegen letztlich daran wie gut verschiedene Sprachen unterstützt sind oder andere Features, wie zum Beispiel das dynamische Umschalten zwischen Sprachen in einem Audio-Strom.
- AWS Lex
- Google Cloud Speech API
- Houndify API
- IBM Speech to Text
- Microsoft Bing Voice Recognition
- Wit.ai
All diese Dienste laufen aber in der Cloud und bieten keine Offline-Fähigkeit. Für eine Offline Spracherkennung in IoT Devices gibt es aber eine Reihe kommerzielle und Open-Source Produkte. Wir möchten Entwicklern zwei besonders empfehlen: CMU Sphinx und Snowboy Hotword Detection. CMU Sphinx ist ein Open Source Speech Recognition Toolkit und stellt über 20 Jahre Lernerfahrung in einer BSD-artigen Lizenz zur Verfügung, die den Einbau in kommerzielle Produkte erlaubt. Hier kann auch lokal im Device weiter gelernt werden. Geht ein Mitarbeiter mit unscharfer Aussprache allerdings an ein anderes Device, wird er wahrscheinlich wieder zunächst schlecht verstanden. Vergleichbar mit CMU Sphinx ist Picovoice ein vollständiges Offline-Konzept und findet sich komplett als Source auf https://github.com/Picovoice/Porcupine. Allerdings ist Picovoice noch nicht so “erfahren” wie CMU Sphinx.
- CMU Sphinx
- Mozilla DeepSpeech und Common Voice
- Nuance
- Picovoice.ai
- Snips
- Snowboy Hotword Detection
- Porcupine
Snips und Snowboy Hotword Detection sind interessante Hybride zwischen Cloud-Dienst und Offline Tooling. Dabei kann man in der Cloud zunächst die nötigen Keywords trainieren lassen. Das ist besonders gut für technische Fachbegriffe, die sonst in der natürlichen Sprache kaum auftauchen. Denken Sie an Fachbegriffe aus dem Maschinenbau. Hier lassen Sie einfach 20 repräsentative Personen die Fachbegriffe aussprechen und laden diese Audioströme in die Snowboy Cloud. Nach kurzer Zeit steht das Machine-Learning Pattern zum Download bereit. Die Spracherkennung kann danach vollkommen offline stattfinden. Nachdem die Software eine Weile in der Produktion und im Feld ist, kann man immer wieder anonymisierte Audio-Aufnahmen in die Cloud laden um die Erkennung spezieller Keywords weiter zu verbessern. Porcubine ist ebenfalls eine gute Key-Word detection die sich für “always listening” Systeme eignet. Ähnlich funktioniert auch das DeepSpeech Opensource Projekt von Mozilla. Hier kann der Lernprozess mit Tensorflow in der Cloud stattfinden, oder auch offline weiter gehen, wenn dann genug Rechenleistung da ist.
Natürlich sind die großen Speech-Recognition Engines in der Cloud nur so gut geworden, weil Millionen von Menschen täglich mit ihnen sprechen. Der Lernerfolg daraus ist der große Asset und die Marktmacht der Internet-Konzerne, nicht hauptsächlich die Algorithmen, die wie Tensorflow ja selbst Open Source sind. Genau hier setzt das Common Voice Projekt von Mozilla an. “Echte” Menschen werden gebeten jeden Tag ein paar Sätze in ihrer Sprache vorzulesen oder die Aussprache durch den Computer zu validieren. Das Ergebnis wird dann wieder in alter Open-Source-Manier frei zu Verfügung gestellt und zum Beispiel von DeepSpeech offline verwendet werden. Der crowd-sourced Ansatz geht hierzulande noch nicht ganz auf da er einfach nicht bekannt genug ist. Deshalb werden neben Menschen auch Hörbücher eingelesen und in Sprachmuster umgerechnet. Ein toller Ansatz um von kommerziellen Lernmustern unabhängig zu werden (voice.mozilla.org/de). Experten wie Prof. Dr. René Peinl glauben fest daran, dass Ansätze auf Basis tiefer neuronaler Netze wie DeepSpeech langfristig überlegen sind.

Letztlich bieten die meisten Speech Recognition Engines zunächst einen korrekt geschrieben Strom von Sätzen, egal wie sie die Spracherkennung gelernt haben. Schon fast als Nebenprodukt bei der Konstruktion eines grammatikalisch korrekten Satzes, entsteht ein “Tokenized Command” wie in diesem Beispiel:
“Blinker links an!”
Request: Fahrzeug-Steuerung
Object: Blinker
Attribute: links an
oder
“Wie komme ich zu Crisp Research in Kassel?”
Request: Weg (Synonym Navigation)
Object: Crisp Research
Attribute: Kassel
Je nach Speech-Recognition-Engine kann dieses Tokenmodell sehr unterschiedlich sein. Das erste Beispiel ist relativ einfach. Der Satz besteht praktisch nur aus trainierbaren Keywords. Der zweite Satz jedoch benötigt einiges Mehr an Intelligenz. Hier zeichnet sich bereits der Unterschied zwischen einem Speech-Recognition und einer echten “Natural-Language Conversation” ab. Bevor wir dies beleuchten, schauen wir aber was noch alles Offline möglich ist mit Bezug auf die Komponenten im ersten Bild ganz oben.
Skill-Implementation kann überall sein
Die Skill-Implementierung reagiert einfach auf den “Event” eines auftauchenden Keywords, wertet den Kontext aus und führt eine Aktion aus. Praktisch alle Speech-Recognition-Engines können auf die Implementierung solcher Skills überall zugreifen. Damit kann man von einer Offline-Engine auch auf eine Custom-Skill-Implementation in dieser Offline-Location verzweigen. Die Skill-Implementation ruft dann wieder die APIs eines IoT Devices auf und führt die gewünschte Aktion aus. Keine Daten verlassen dabei die lokale Umgebung.
Natural Language Conversation
Zwischen dem Erkennen einfacher Keywörter und einer richtigen Konversation in natürlicher Sprache ist ein riesiger Unterschied. Letzteres ist dann auch Aufgrund der Komplexität und der notwendigen Lernprozesse gar nicht offline möglich. Um die Grenze klar zu verstehen nehmen wir einmal das Beispiel der Navigation oben.
“Wie komme ich zu Crisp Research in Kassel?”
ist bereits eine Frage die nicht so einfach zu “tokenizen” ist. Es ist nicht klar dass Crisp Research der Name einer Firma ist. Seit fast 20 Jahren sind in Oberklasse-Autos sprachgesteuerte Navigationsgeräte verbaut die das Problem durch ganz einfache Dialoge umgehen. Dabei werden die einfachen Dialoge wie “Geben Sie den Name der Straße ein: … Geben Sie den Namen der Stadt ein: …” verwendet. Das ist sehr einfach, weil das phonetische Modell beispielsweise nur den Klang der meisten Städte kennen muss. Ein Sprachmodell gibt es gar nicht. Solche einfachen Sprachsteuerungen sind heute in guter Qualität auch offline eine Leichtigkeit für Open-Source Toolkits wie das CMU Sphinx.
Suchen wir etwas mehr Intelligenz, wird man heute sogar schon bei der Eingabe in Suchmaschinen fündig. Die Google-Suche nach “navigation crisp research kassel” löst sofort “crisp research” als Firmenname auf, sucht die Adresse unseres Büros in Kassel heraus und zeigt die Google-Maps Navigation dorthin an.

Eine echte Konversation in natürlicher Sprache versteht darüber hinaus natürliche Sprache ohne einem festen Aufbau zu folgen. Experten nennen dies Natural Language Understanding (NLU). Auf die Frage “Wie komme ich zu Crisp Research in Kassel?”, wünscht man sich vom Sprachassistent unter Umständen eine Gegenfrage wie “Möchtest Du mit dem Zug oder mit dem eigenen Auto fahren” und es entsteht eine Konversation ….”Auto”….”Neben dem Crisp Research Office ist ein Parkhaus. Möchtest Du dies als Ziel?” … “Ja” usw.
Die auffälligsten zwei Unterschiede zwischen der einfachen Keyword basierten Sprachsteuerung und einer Konversation in natürlicher Sprache ist einerseits die Fähigkeit des Computers den Kontext von einem Frage-Antwort Spiel ins nächste zu behalten. Hier ist Siri noch lange nicht, Alexa ein wenig und Google am weitesten. Der zweite augenfällige Unterschied ist der transparente Zugriff auf Wissen im Internet. Mit Blick auf die erste Abbildung oben durchsucht die künstliche Intelligenz hinter der “Natural Language Conversation” das Netz und lernt selbst, dass es sich bei “Crisp Research” sehr wahrscheinlich um eine Firma und nicht um den Namen einer Person handelt. Einige kommerzielle Speech Recognition Engines wie die bekannten Produkte Speech Recognizer VoCon Hybrid und die Speech Synthesis Vocalizer Expressive aus dem Hause Nuance wagen sich auf komplett offline mit Hilfe von Partner wie der Paragon-Semvox auch immer weiter in Richtung Offline KI. Die Sprachsteuerung in einigen modernen Autos ist darauf aufgebaut. Es handelt sich aber um geschlossene und kommerziell lizenzierte Software und Learning Pattern.
Das Fazit für IoT Architekten und Projektentwickler liegt auf der Hand: Es geht selbst auf leistungsschwachen Edge-Computern eine Menge Sprachsteuerung Offline! Gegebenenfalls bringt die Kombination aus anonymen Lernprozessen in der Cloud und nicht-lernenden Offline Engines die besten Ergebnisse. Um sich nicht zu sehr auf eine Sprachassistenz-Engine bzw. Plattform festzulegen, können auch Bibliotheken helfen die eine Engine-unabhängige Abstraktion zur Verfügung stellen, wie die SpeechRecognition Library für Python. Damit lassen sich viele Szenarien ohne großen Entwicklungsaufwand realisieren. Je nach Wahl der Engine ist das ganze System offline um Bedenken der Privatsphäre zu respektieren. Eine richtige Natural Language Conversation ist heute realistisch – wenn überhaupt – nur mit cloud-basierten Dienste möglich. Hier forschen Informatiker wie Prof. Pein jedoch schon an zukünftigen Offline Möglichkeiten. Für die Szenarien die Aufgrund der mangelnden (mobilen) Konnektivität in Deutschland nicht immer auf einen Cloud-Service zugreifen können, bietet es sich heute an, ein hybrides Konzept zu implementieren. Falls man Online ist, funktionieren natürliche Konversationen und falls die Cloud nicht erreichbar ist, geht zumindest noch die einfachere Sprachsteuerung wie “Blinker links an!” oder “Maschine stop!”.
Berichten Sie uns gerne von ihren sprechenden IoT Devices!